gus-bus
-
Posts
10 -
Joined
-
Last visited
-
Days Won
2





gus-bus's Achievements
")
-
Hi Surfincow, Which KB(s) did you apply? If it was only the WSUS patch applied, I'm wondering if a person needs to apply the other KB's to the other servers for this to issue to become less prevalent/disappear? Which SCCM release are you running? If you aren't running the latest, I would try to get there as you may see better results from those updates as well. /Gus
-
Hi Bebop, This is great news! We'll install these updates in our environment and see what happens. Thanks again for everyone's contributions on this one. Hopefully others will find some value from our headaches. /Gus
-
So a brief update here on the MS ticket submitted. Of course just before the MS call, we had things fairly leveled off with our WSUS/SCCM environment, but we still dug into it. Here's the closing of the ticket: -------------------------------------------------------------------------------------------- SYMPTOM: 2016 server 'sqlsbx02' failing scan with error code '0x8024401c' on SCCM server 'srvsccmprd01'. CAUSE: High CPU utilization. RESOLUTION: We declined KB 4034658 and removed the obsolete updates from SUS DB which helped in resolving the issue. Also the resolution for the issue mentioned in KB4034658 is being worked upon and will soon be released publically. You can refer to the following articles which are useful in bringing down high CPU utilization: https://blogs.msdn.microsoft.com/the_secure_infrastructure_guy/2015/09/02/windows-server-2012-r2-wsus-issue-clients-cause-the-wsus-app-pool-to-become-unresponsive-with-http-503/ https://blogs.technet.microsoft.com/configurationmgr/2016/01/26/the-complete-guide-to-microsoft-wsus-and-configuration-manager-sup-maintenance/ -------------------------------------------------------------------------------------------- In addition to the above references we also performed the following against the WSUS database in SQL: Obsolete Updates Check Query: exec spGetObsoleteUpdatesToCleanup Cleanup Query: DECLARE @var1 INT DECLARE @msg nvarchar(100) CREATE TABLE #results (Col1 INT) INSERT INTO #results(Col1) EXEC spGetObsoleteUpdatesToCleanup DECLARE WC Cursor FOR SELECT Col1 FROM #results OPEN WC FETCH NEXT FROM WC INTO @var1 WHILE (@@FETCH_STATUS > -1) BEGIN SET @msg = 'Deleting ' + CONVERT(varchar(10), @var1) RAISERROR(@msg,0,1) WITH NOWAIT EXEC spDeleteUpdate @localUpdateID=@var1 FETCH NEXT FROM WC INTO @var1 END CLOSE WC DEALLOCATE WC DROP TABLE #results That's what I have so far and to be honest, things have significantly improve post WSUS database maintenance which took place before the support call. /Gus
-
Exactly, we're not the only people with this issue. TrialandError, great article/find! I appreciate you guys posting here as this has been frustrating to deal with...again. I've got our environment partially tweaked to referenced the article from TrialandError and it seems to be functioning in bandaid capacity until we hear something further from MS. As for the Express files, we had tried that in the last couple of weeks with not the world's greatest success and our results matched what many others had been posting. If that feature-set begins to work properly I could seem some value; however, with the size of some of the download files, it just isn't feasible to send to our low bandwidth sites. I will warn you that once you start synchronizing the updates, it hasn't been just a simple checkbox to uncheck and the files don't show up anymore. In our environment the files continued to download time and time again. About 1/2 hour ago I too submitted a ticket with MS to get another person hitting them up on this issue as it is rather important in my opinion. Hopefully we'll get access to this magical patch that may fix the issue. I'll let you know what I hear. /Gus
-
Hello Creaton, I've actually moved to a different organization since the original posting and to my knowledge they have not had an issue since. However, at the new organization I am at we are currently seeing a similar issue again with Server 2016 VM's. I've made the required tweaks from the posting above but didn't notice a full fix on it. I do want to point out that in this new environment they have the server patching and workstation patching in two completely separate SCCM environments. The server patching is done quarterly so this server isn't touched all that often. I also want to note that Server 2008, 2008 R2, 2012, and 2012 R2 are receiving their SCCM updates flawlessly, it's just the 2016 boxes. I've bumped up the memory configurations quite a bit and still see the issue so there are a few maintenance items that needed to be checked, primarily WSUS (see links in the post above). In this server SCCM environment the expire superseded updates and WSUS clean up were unchecked so that is likely the issue at this time and I am working through that process now. Are you only seeing the issue on the 2016 servers in your environment or everywhere? /Gus
-
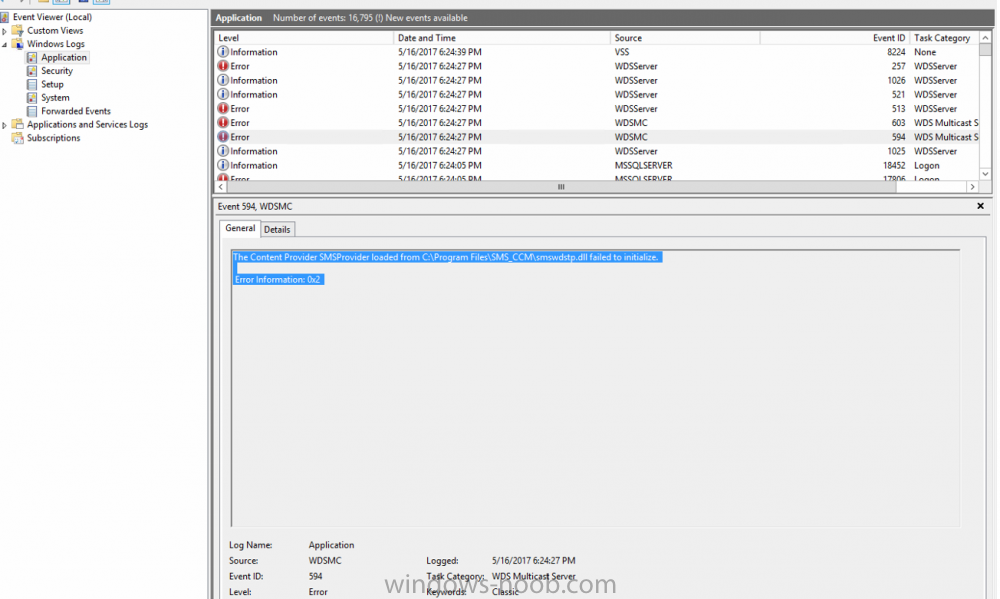
Hello, We recently turned on multicast in our SCCM environment, which has turned on fine on all distribution points; however, when we turn it on within our Primary Site server the WDS server enters a stopped state and will not start until you remove the multicast check box for that server. The error we see is: "The Content Provider SMSProvider loaded from C:\Program Files\SMS_CCM\smswdstp.dll failed to initialize. Error Information 0x2." We have found other articles posted experiencing a similar issue and the resolution for most was to remove the PXE, WDS, Multicast feature/roles, reboot, clean out the RemoteInstall folder, and reinstall. When we do that it starts for a few seconds and then stops the service at which point it cannot be restarted until removing the Multicast feature within the SCCM console. We are running on Configuration Manager 1702 which is running on top of Server 2012 R2 x64 - VMware virtual machine. Any thoughts on this would be greatly appreciated. Thanks /Gus
-
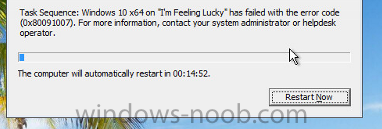
Hello, We recently turned on Multicast within our SCCM environment and have been progressively searching for an answer to the following task sequence error: Task Sequence has failed with error code (0x80091007). In searching through the client workstation's SMSTS.log file we see the following: 1. pDownload->Download(pwszServer, pwszNamespace, pwszRemoteObject, pwszLocalObject, uCacheSize), HRESULT=800706ba (e:\nts_sccm_release\sms\server\mcs\consumer\mcclient.cpp,120) ApplyOperatingSystem 5/16/2017 5:25:34 PM 1712 (0x06B0) 2. Encountered error transfering file (0x800706BA). ApplyOperatingSystem 5/16/2017 5:25:34 PM 1712 (0x06B0) 3. Sending status message: SMS_OSDeployment_PackageDownloadMulticastStatusFail ApplyOperatingSystem 5/16/2017 5:25:34 PM 1712 (0x06B0) Since it is unable to transfer the file via multicast you get the following: 4. Hash could not be matched for the downloded content. Original ContentHash = C61CCE4D5DA21B9A531B268C6690D5A1D79867A1CC428E84E96C9CDDFCE1B94A, Downloaded ContentHash = ApplyOperatingSystem 5/16/2017 5:25:34 PM 1712 (0x06B0) 5. 0L == TS::Utility::VerifyPackageHash (pszContentID, sDestination), HRESULT=80091007 (e:\cm1702_rtm\sms\framework\tscore\resolvesource.cpp,3291) ApplyOperatingSystem 5/16/2017 5:25:34 PM 1712 (0x06B0) 6. DownloadContentAndVerifyHash() failed. 80091007. ApplyOperatingSystem 5/16/2017 5:25:34 PM 1712 (0x06B0) 7. Installation of image 1 in package DL100069 failed to complete.. The hash value is not correct. (Error: 80091007; Source: Windows) ApplyOperatingSystem 5/16/2017 5:25:34 PM 1712 (0x06B0) We've verified the proper core switch configurations for across VLAN multicasting and have also ensured the OS, driver packages, etc are set to "allow multicast" within SCCM. We've also redistributed the content to the distribution points using multicasting to ensure there isn't an issue there. With how quickly it fails it doesn't appear that it is even able to pull the OS multicast file. In looking at the distribution point we have enabled for multicast we see the following in the MCSIsapi.log: 1. Could not create an instance of the MCSISAPIProxy object (0x80070005) McsIsapi 5/16/2017 8:00:03 PM 3000 (0x0BB8) 2. HealthCheckRequest::HandleMessage failed with errorcode (0x80070005) McsIsapi 5/16/2017 8:00:03 PM 3000 (0x0BB8) 3. Failed to process HEALTHCHECK request for client ffffffff-ffff-ffff-ffff-ffffffffffff McsIsapi 5/16/2017 8:00:03 PM 3000 (0x0BB8) 4. MCSRequestHandler::HandleMessage for Op HEALTHCHECK failed with server errorcode 2052 McsIsapi 5/16/2017 8:00:03 PM 3000 (0x0BB8) 5. Looking for: E:\SCCMContentLib\DataLib\DL100069* McsIsapi 5/16/2017 8:06:52 PM 2972 (0x0B9C) 6. Looking for: E:\SCCMContentLib\DataLib\DL100069* McsIsapi 5/16/2017 8:35:22 PM 2972 (0x0B9C) Even though it is looking for that package, the distribution point has it when you search in that location. We've found several forums/articles with people who have similar issues but none of the items they recommend trying to seem to work for us. The closest article to what we are experiencing is the following: http://thoughtsonopsmgr.blogspot.in/2014/08/sccm-2012x-multicast-another-bites-dust.html We are running Configuration Manager 1702 running on Server 2012 R2 x64. All of the distribution points are also on Server 2012 R2 x64. I would also like to add that as soon as we turn off multicast in the distribution point, it works flawlessly on unicast. Any thoughts on where to go on this one would be greatly appreciated. Thanks /Gus
-
Sorry folks, I think i got this one on my own. Below is what I have found: **The IIS Worker service was using high amounts of CPU. After further investigation we found the issue to be with the WsusPool Worker Process on the server. It would climb up and service a few clients and then recycle on a regular basis. We noticed the same IP addresses were in the "current requests" for the worker service each time before it crashed. It was the Windows Server 2016 servers, which were coincidentally the Advanced Threat Analytics servers (not related). ** After many searches and digging on this topic it would appear it is an IIS configuration change issue, which is reflected in the following articles: http://serverfault.com/questions/522832/problems-with-sup-on-sccm-2012-sp1 http://blog.coretech.dk/kea/house-of-cardsthe-configmgr-software-update-point-and-wsus/ https://social.technet.microsoft.com/Forums/en-US/a629c131-1c12-4803-a479-e5c6ca784b10/sccm-wsus-failed?forum=configmanagergeneral http://stackoverflow.com/questions/16162524/how-to-increase-memory-and-cache-size-for-application-pool-in-iis-7-efficiently https://blogs.msdn.microsoft.com/the_secure_infrastructure_guy/2015/09/02/windows-server-2012-r2-wsus-issue-clients-cause-the-wsus-app-pool-to-become-unresponsive-with-http-503/ So here are the settings that I changed within IIS on Private Memory Usage Increase (for Recycling Conditions) - Private Memory Usage increase to 8388608 KB Output Cache Increase (for response file size): - Output Cache Settings increase to 1048576 (in bytes) Maximum Worker Processes: -Maximum Worker Processes from 1 to 0 (System must be NUMA aware for this and will essentially trigger as many worker processes as there are NUMA nodes). Thanks /Gus
-
Hello SCCM Folks, We are seeing an abnormally high CPU usage on our primary site server and have tracked it down to the WSUSPool of the IIS Worker Process. Digging even further we are finding that it is being caused by our Server 2016 boxes hitting the WSUS site consistently almost every three minutes. We run our primary site server on Server 2012 R2 using System Center Configuration Manager 1610 (site version: 5.0.8458.1000). The resources on this machine have been sufficient for some time and serving our needs until recently with the CPU being maxed out. We have thrown additional resources at it, but to no surprise those are consumed quickly and not the answer. Our Server 2016 VM's are seeing the following error in the WUAHandler.log: -------------------- OnSearchComplete - Failed to end search job. Error = 0x8024401c. WUAHandler 2/1/2017 12:52:55 PM 2844 (0x0B1C) Scan failed with error = 0x8024401c. WUAHandler 2/1/2017 12:52:55 PM 2844 (0x0B1C) The new content version (191) of update source is less than before (499), continuing. WUAHandler 2/1/2017 12:52:55 PM 5040 (0x13B0) --------------------- I have tried a few different suggestions from other forums about changing the proxy settings in Internet Options, which did not resolve the issue (we do not use a proxy). I am able to get the 2016 boxes to point to Microsoft Update servers externally for patches at this time, but these settings are changed back to our internal WSUS server per Group Policy as they should just to see the same errors. The group policy we have in place is pointing all OSes to the same WSUS path (our primary site server) with no issues on 2008 R2, 2012 R2, Windows 7, 8, or 10. Has anyone else seen this issue or have any thoughts? We started seeing this on the January 24th, 2017 according to the performance chart in VMware for that server. I would appreciate any feedback. Thanks /Gus
-
Hi Hannes, I too am having this exact same issue on our primary site server. I'm fairly new to my current organization but I have had experience with SCCM and this one is a new one. As you said, it certainly seems to be something in relation to 1511. It gets to this point: File C:\Windows\ccmsetup\{A468E717-9650-405E-B971-F5BE44093864}\client.msi installation failed. Error text: ExitCode: 1603 Action: CcmCompileSqlCEScripts. ErrorMessages: Setup was unable to compile Sql CE script file C:\Program Files\SMS_CCM\StateMessageStore.sqlce. The error code is 80004005. ---------------------------------------- Then you see the rollback: MSI: Action 7:48:03: Rollback. Rolling back action: --------------------------------------- We are not seeing this issue with any other clients in our organization except for the primary site server at this time. If anyone has run across this or has ideas I would greatly appreciate the info. Thanks /Gus-Bus